

OpenAI vs Anthropic vs Google: What the Latest AI Benchmarks Really Mean for the Market | AI Nexus Global
The latest AI benchmarks show that the artificial intelligence market is moving beyond simple leaderboard culture. The real story now is how different frontier AI models perform across reasoning, coding, browsing, tool use, and practical workflow execution.
That is why the current OpenAI vs Anthropic vs Google debate matters so much. Enterprises are no longer selecting models based only on hype or headline launches. They are making decisions based on fit, reliability, deployment context, and long-term business value. In that environment, an AI benchmark comparison becomes useful only when it is connected to a real market strategy.
The benchmark race is becoming more practical
For much of the past two years, the AI conversation was dominated by model launches, screenshots, and viral comparisons. That phase is now fading. The market is becoming more serious, and buyers want to know which model performs best for real use cases like software engineering, advanced reasoning, agentic browsing, and computer interaction.
This makes the latest AI benchmarks more important than earlier rounds. They no longer function only as technical scorecards. They now shape enterprise AI model selection, procurement decisions, product choices, and even investor perception around where value is likely to concentrate across the AI ecosystem.
The most important shift is this: there may not be one universal winner. One model may lead in coding, another in browsing, and another in scientific reasoning. That means OpenAI vs Anthropic vs Google should be understood as a competition across categories, not a one-number verdict on intelligence.
What the chart shows
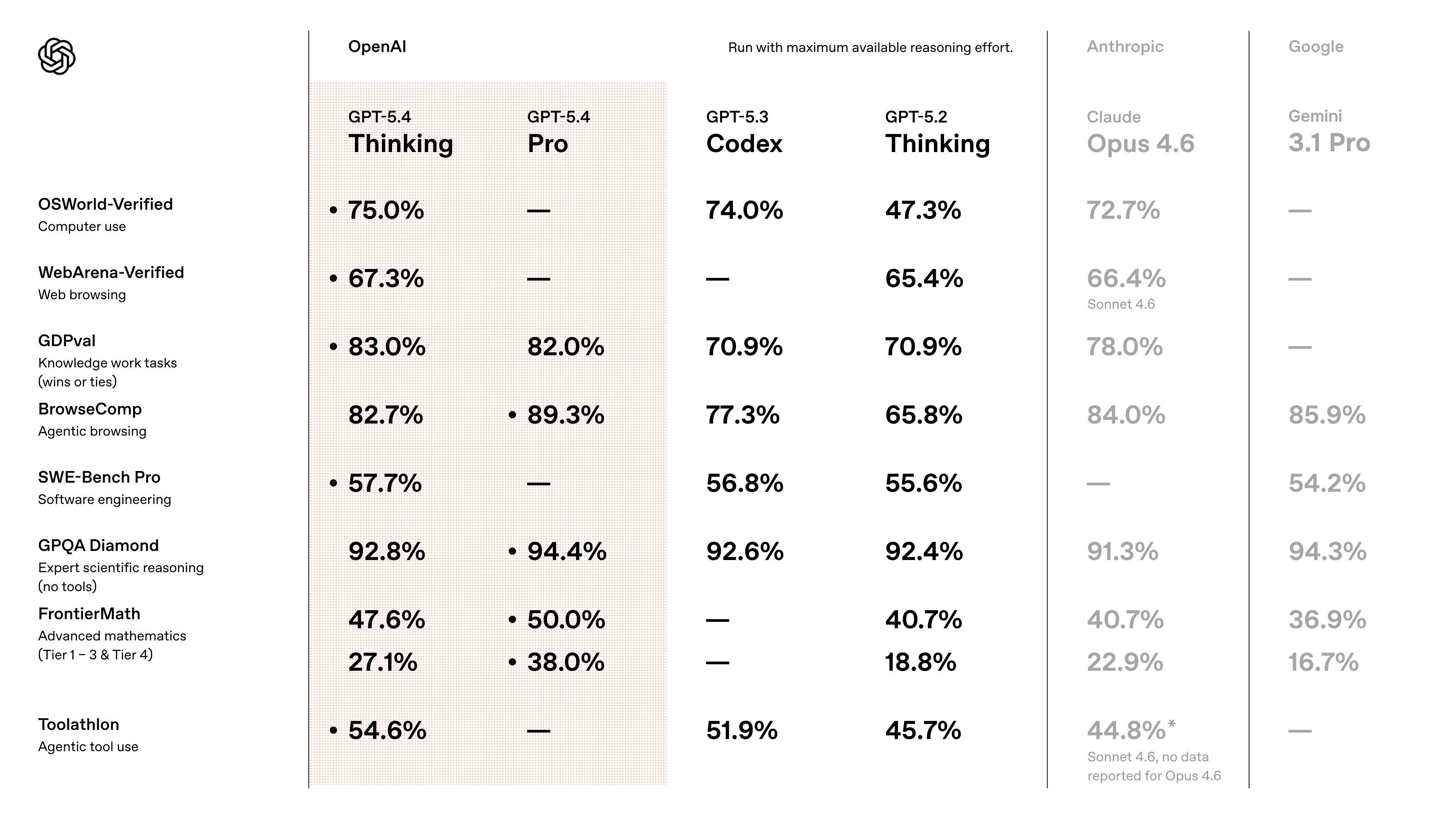
| Model | Main takeaway |
|---|---|
| GPT-5.4 Thinking | Strong all-round performance across reasoning, browsing, coding, maths, and tool use |
| GPT-5.4 Pro | Very strong on GDPval, BrowseComp, GPQA Diamond, and FrontierMath |
| GPT-5.3 Codex | Strong in computer use, coding, browsing, and tool use |
| GPT-5.2 Thinking | Solid across most categories, but below GPT-5.4 family |
| Claude Opus 4.6 | Very competitive in reasoning and browsing-related tasks |
| Claude Sonnet 4.6 | Notable on WebArena-Verified and Toolathlon |
| Gemini 3.1 Pro | Strong on BrowseComp and GPQA Diamond |
Easiest takeaways
OpenAI has the broadest spread of strong scores across the chart.
GPT-5.4 Pro stands out on BrowseComp, GPQA Diamond, and FrontierMath.
Anthropic stays competitive in high-value reasoning and browsing areas.
Gemini 3.1 Pro is especially strong in BrowseComp and GPQA Diamond.
GPT-5.2 thinking is solid, but the newer OpenAI models are clearly stronger overall.
Why this matters for enterprise AI model selection
For enterprises, the challenge is no longer lack of access. It is decision overload. A strong score in one area does not automatically translate into business value across every department. A model that performs well in reasoning may not be the best option for browser-heavy automation, while a model that performs strongly in coding may still raise questions around integration, security, or cost.
That is why enterprise AI model selection is becoming one of the hardest decisions in the artificial intelligence market. Teams need to compare technical performance with governance requirements, deployment readiness, vendor support, and internal capability. The benchmark layer matters, but it is only one part of a much larger decision process.
This is also why the AI ecosystem itself matters more than ever. As model capabilities expand, buyers need trusted ways to compare providers, discover vendors, understand use cases, develop skills, and track policy changes. Without that infrastructure layer, the market stays fragmented even as the technology gets stronger.
AI Nexus Global is designed around exactly that structural gap. It combines AI stories, a verified AI business directory, an AI marketplace, a lead generation engine, an events hub, a community layer, a learning and careers hub, a government and policy tracker, and a hyper-personalised intelligence layer into one unified platform for the AI economy. Its mission is to connect AI leaders, entrepreneurs, investors, enterprises, policymakers, developers, and learners in a single ecosystem that functions as a global operating system for the AI market.
The bigger market signal
The deeper lesson from this AI benchmark comparison is not just that one model leads another by a few points. It is that the market is shifting from model spectacle to ecosystem execution.
In the next stage of the artificial intelligence market, the winners will not only be the companies building the best frontier AI models. They will also be the platforms that make those models easier to discover, compare, deploy, govern, and scale across real-world business environments. That is where long-term value is likely to form across the AI ecosystem.
Explore AI Nexus here: https://ainexus.prabisha.com/